COMP7103 Data Mining
Topic 1 Introduction
Decision-Support System (DSS)
- A decision-support system (DSS) is a system that assists decision makers to make important decisions for an organization or business
- KDD and data mining are important components in many DSS’s
Data and Knowledge
- Data
- A collecion of facts about certain group of objects
- Pattern
- Certain characteristics of data that are frequently observed
- Knowledge
- Some general rules about the objects
Data Warehouse
- An integration of various departmental databases (organization-wide data)
- Avoids overloading local operational databases
- A convenient place where KDD and data mining applications are performed
- Provide data mining algorithms an easy access to the required data
- Wrappers
- Extract
- Transform
- Can also be used to support other DSS tools, e.g. On-Line Analytical Processing (OLAP) - analyze large amount of data, Online Transaction Processing (OLTP)
Data Mining and KDD
- KDD (Knowledge Discovery in Databases)
- A process of discovering useful knowledge from big collection of data
- Data Mining
- A step within the KDD process in which interesting patterns are found. Some of these patterns are then interpreted and transformed into useful knowledge.
Data Mining is a step in the whole KDD process
KDD is a process of identifying patterns in data and deriving knowledge from them
- valid
- novel
- potentially useful
- understandable
Data Mining
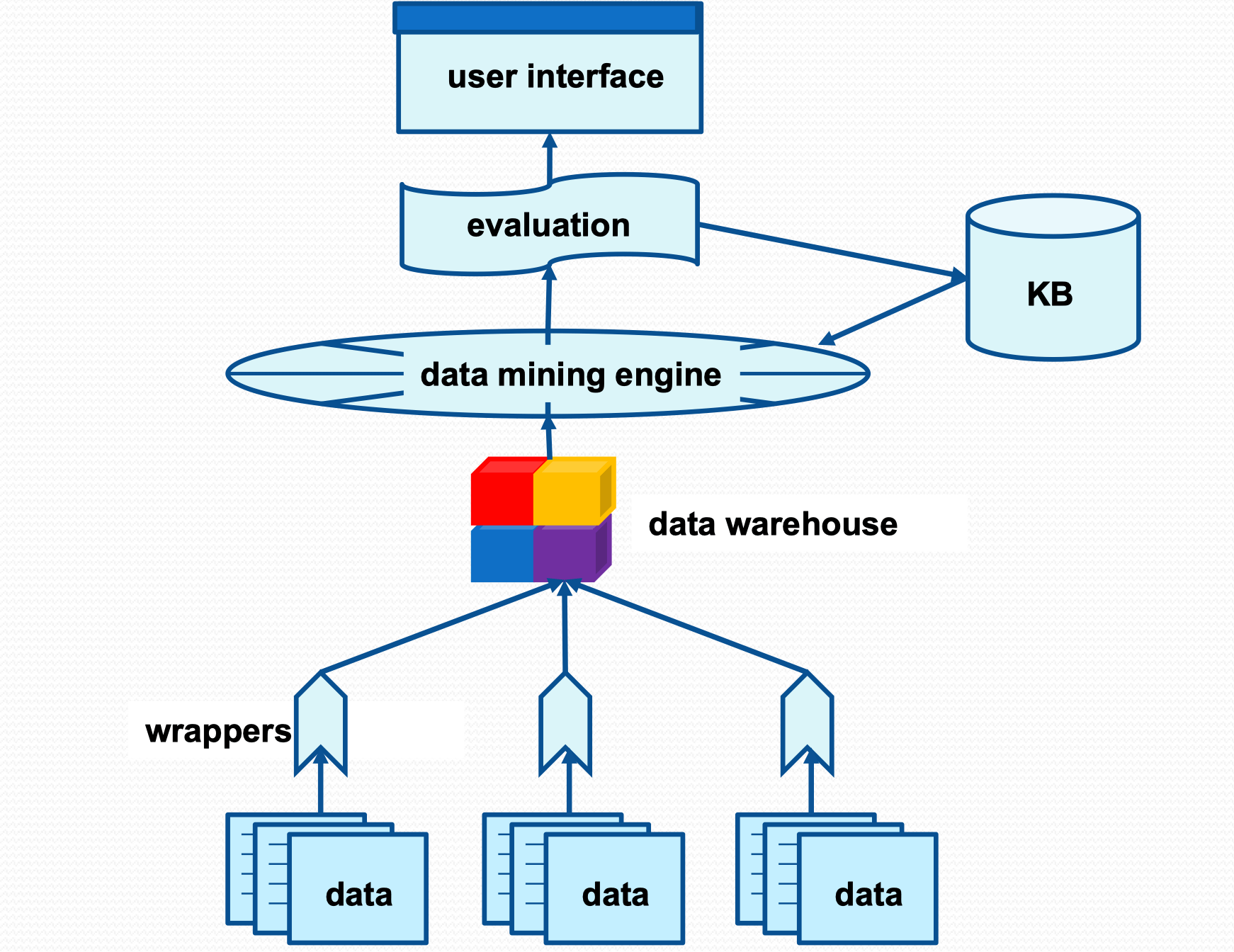
Databases
- Bottom layer of the architecture
- Contains data sources (raw data)
Traditional Database usually only provides the functions of storing and retrieving facts
The knowledge resulting from data mining should carry certain degree of predictive ability or descriptive (explanatory) ability (or both)
Data Mining Engine
- Applies data mining algorithms on data
- Provides multiple functionality
Evaluation Module
- Allow users to specify what is/isn’t interesting
Knowledge Base
- Capture domain specific knowledge
- Stores the rules generated by data mining
Graphical User Interface
- Presents mined patterns and rules to users in an easy-to-visualize way
- Provides feedback mechanisms for the users to specify the criteria of interestingness
- Provides a query language or query interface for users to select and retrieve
Challenges of Data Mining
- Technical
- Scalability
- Dimensionality
- Data stream
- Data
- Complex and heterogeneous data
- Data quality
- Privacy
- Data ownership and distribution
- Privacy preservation
- Results
- Interpretation of patterns
The KDD Process
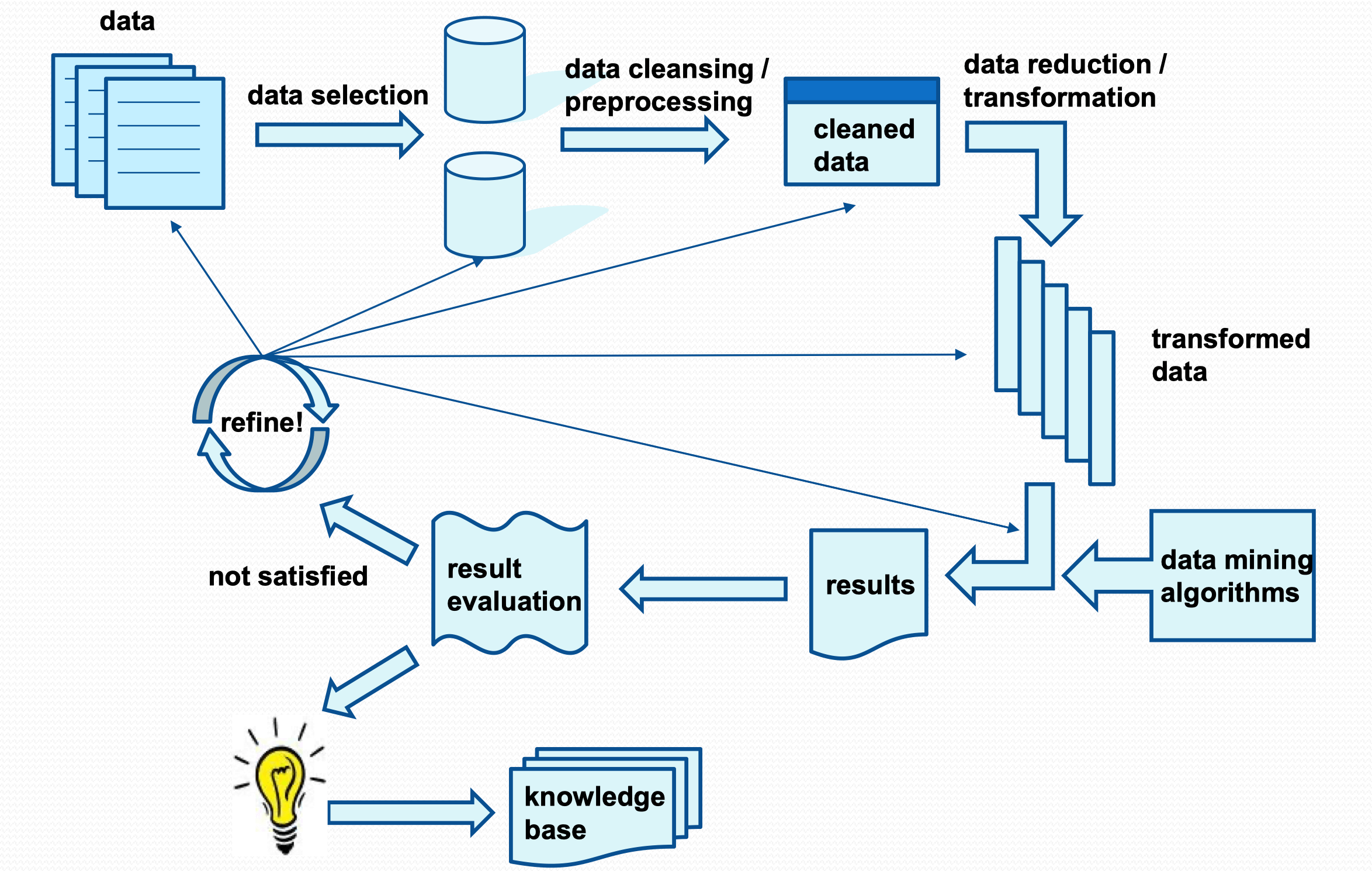
- Step 1: Goal Setting
- Understand your application domain
- Obtain prior known knowledge
- Step 2: Data Collection
- Characteristics
- Where to find
- How to store
- Step 3: Data Cleaning and Preprocessing
- Missing data
- Incorrect data (noise)
- Outliers
- Step 4: Data Reduction and Transformation (or Preparation)
- Compact data into a form
- Improve data mining algorithms
- Step 5: Data Mining
- Pick a data mining model
- Pick a data mining algorithm
- Apply the algorithm to the data
- Step 6: Result Evaluation
- Check the results and goals
- Refine and re-run (if not)
- Step 7: Knowledge Consolidation
- Document
- Report
Iterative and Interactive
- Some steps of the process need to be refined, and the whole process be repeated
- Certain amount of human involvement is needed to monitor and to fine tune the steps
Prediction
- Uses database records that describe information about past behavior to automatically generate a model (or rule) that can predict future behavior
Description
- Derive patterns that summarize the underlying relationships in data and to describe the characteristics of data
OLAP (On-Line Analytical Processing)
- View data in a multi-dimensional model (a data cube)
- Fast aggregation
- Summarization
Example
- Selection -> Group-by -> Summarization
Classification
Supervised learning
- Goal
- Unseen records should be assigned a class (accuracy)
- Approach
- Given a training set
- Learn classifier
- Find a model
- Test the model using test set
Example
- Direct Marketing
- Reduce cost of mailing by targeting a set of consumers likely to buy a new cell-phone product
Regression
- Goal
- Preduct a value of numerical variable based on the values of other variables
Example
- Predicting sales amounts of new product based on advertising expenditure
- Predicting wind velocities as a function of temperature, humidity, air pressure, etc.
Clustering
- Given a set of data objects with a set of attributes and similarity measure
- Find clusters (e.g. distance-based clustering)
- Maximize the intra-cluster similarity
- Minimize the inter-cluster similarity
- Objects in one cluster are more similiar to one another

Example
- Document Clustering
- To find groups of documents that are similar to each other based on the important terms they contain
Association Rule Discovery
- Given a set of records each of which contains some items from a given collection
- Goal
- Produce dependency rules which predict occurrence of an item based on occurrences of other items
Example
- Marketing and Sales Promotion
Sequence Analysis
- Given a sequence database contains sequences of events
- Find sequences
- Interesting
- Frequently occurring
- Predict future behavior.
Example
- Renting movies
- Buying habits
- Web serving behavior
- Web log analysis
